

Spark基础
一、Spark简介
定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提 高了运行速度、并提供丰富的操作数据的API提高了开发速度。
统一分析引擎?
Spark是一款分布式内存计算的统一分析引擎。 其特点就是对任意类型的数据进行自定义计算。
Spark可以计算:结构化、半结构化、非结构化等各种类型的数据结构,同时也支持使用Python、Java、Scala、R以及SQL语言去开发应用 程序计算数据
Spark VS Hadoop
Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于进程之间是互相独立的,每个task独享进程资源,没 有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低.比如多个map task读取不同数据源文件需要将数据源加 载到每个map task中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行 单位,但缺点是线程之间会有资源竞争.
Spark的四大特点
- 速度快
- 易于使用
- 通用性强
- 多种运行方式
Spark的架构角色
Master角色,管理整个集群的资源 – 类比于YARN的ResourceManager
Work角色,管理单个服务器的资源 – 类比于YARN的NodeManager
Driver角色,管理单个Spark任务在运行的时候的工作 – 类比于YARN的ApplicationMaster
Executor角色,单个任务运行的时候的一堆工作者,干活的 – 类比于YARN容器内运行的TASK

从两个层面划分:
- 资源管理层面:
- 管理者:Spark是Master角色,YARN是ApplicationMaster
- 工作者:Spark是Worker角色,YARN是NodeManager
- 从任务执行层面:
- 某任务管理者:Spark是Driver角色,YARN是ApplicationMaster
- 某任务执行者:Spark是Executor角色,YARN是容器中运行的具体工作进程
- 资源管理层面:

二、Spark环境搭建 -local
2.1 基本原理
本质:启动一个JVM Process进程(一个进程里面有多个线程),执行任务Task
Local模式可以限制模拟Spark集群环境的线程数量, 即Local[N] 或 Local[*]
其中N代表可以使用N个线程,每个线程拥有一个cpu core。如果不指定N,则默认是1个线程(该线程有1个core)。 通常Cpu有几个Core,就指定几个线程,最大化利用计算能力
如果是local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine.按照Cpu最多的Cores设置线程数


Local 下的角色分布:
资源管理: Master:Local
进程本身 Worker:Local进程本身
任务执行:
Driver:Local进程本身
Executor:不存在,没有独立的Executor角色, 由Local进程(也就是Driver)内的线程提供计算能力
PS: Driver也算一种特殊的Executor, 只不过多数时候, 我们将Executor当做纯Worker对待, 这样和Driver好区分(一类是管理 一类是工人)
注意: Local模式只能运行一个Spark程序, 如果执行多个Spark程序, 那就是由多个相互独立的Local进程在执行
2.2搭建
2.2.1 安装条件
Spark
下载地址:https://dlcdn.apache.org/spark/spark-3.2.0/spark-3.2.0-bin-hadoop3.2.tgz
解压:
tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C /export/server/Python 推荐3.8
JDK 1.8
Anaconda on linux
2.2.2 环境变量
配置Spark由如下5个环境变量需要设置
- SPARK_HOME: 表示Spark安装路径在哪里
- PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
- JAVA_HOME: 告知Spark Java在哪里
- HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
- HADOOP_HOME: 告知Spark Hadoop安装在哪里
这5个环境变量 都需要配置在: /etc/profile中
在porfile文件输入以下配置指令:
export SPARK_HOME=/export/server/spark
export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
PYSPARK_PYTHON和JAVA_HOME 需要同样配置在/root/.bashrc中 输入vim ~/.bashrc
export JAVA_HOME=/export/server/jdk
export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.8
2.2.3 安装相关环境
将所需安装包文件上传到/export文件夹下
安装anaconda
在/export 文件夹下,执行
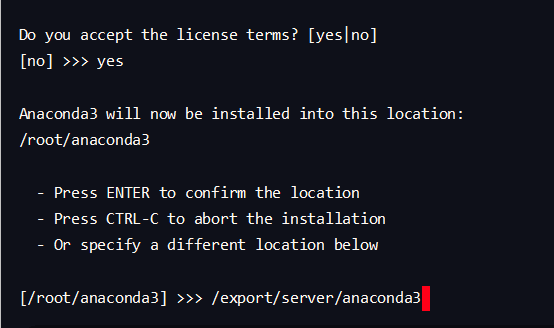
sh ./Anaconda3-2021.05-Linux-x86_64.sh然后选择安装路径到
/export/server/anaconda3目录下,执行安装操作
是否执行初始化:yes

输入
source /export/server/anaconda3/bin/activate启动anaconda配置pyspark环境
在anconda启动后输入
conda create -n pyspark python=3.8输入
conda activate pyspark激活创建的虚拟环境
安装spark
在/export文件夹下执行
tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C /export/server/为spark添加软链接
ln -s /export/server/spark-3.2.0-bin-hadoop3.2 /export/server/spark



2.2.4 启动测试
先进入/export/server/spark目录下:
pyspark
进入bin目录运行
./pysparkpyspark 程序, 可以提供一个交互式的 Python解释器环境, 在这里面可以写普通python代码, 以及spark代码
WEB UI 4040
4040端口是一个WEBUI端口, 可以在浏览器内打开输入:
服务器ip:4040即可打开:
Spark-shell
同样是一个解释器环境, 和
bin/pyspark不同的是, 这个解释器环境 运行的不是python代码, 而是scala程序代码spark-submit (PI)
作用: 提交指定的Spark代码到Spark环境中运行
使用方法:
1
2
3
4
5
6语法
bin/spark-submit [可选的一些选项] jar包或者python代码的路径 [代码的参数]
示例
bin/spark-submit/export/server/spark/examples/src/main/python/pi.py 10
此案例 运行Spark官方所提供的示例代码 来计算圆周率值. 后面的10 是主函数接受的参数, 数字越高, 计算圆周率越准确.对比
功能 bin/spark-submit bin/pyspark bin/spark-shell 功能 提交java\scala\python代码到spark中运行 提供一个 python解释器环境用来以python代码执行spark程序 提供一个 scala解释器环境用来以scala代码执行spark程序 特点 提交代码用 解释器环境 写一行执行一行 解释器环境 写一行执行一行 使用场景 正式场合, 正式提交spark程序运行 测试\学习\写一行执行一行\用来验证代码等 测试\学习\写一行执行一行\用来验证代码等


三、环境搭建-Standalone
3.1 Standalone架构
Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
StandAlone 是完整的Spark运行环境,其中:
Master角色以Master进程存在, Worker角色以Worker进程存在 Driver和Executor运行于Worker进程内, 由Worker提供资源供给它们运行

StandAlone集群在进程上主要有3类进程:
主节点Master进程:
Master角色, 管理整个集群资源,并托管运行各个任务的Driver
从节点Workers:
Worker角色, 管理每个机器的资源,分配对应的资源来运行Executor(Task); 每个从节点分配资源信息给Worker管理,资源信息包含内存Memory和CPU Cores核数
历史服务器HistoryServer(可选):
Spark Application运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息。


3.2 Standalone 环境安装
3.2.1 集群规划
使用三台Linux虚拟机来组成集群环境, 非别是:
node1\ node2\ node3
node1运行: Spark的Master进程 和 1个Worker进程
node2运行: spark的1个worker进程
node3运行: spark的1个worker进程
整个集群提供: 1个master进程 和 3个worker进程
3.3.2 在所有机器配置环境变量
复制anaconda到node2和node3
运行:
1
2scp Anaconda3-2021.05-Linux-x86_64.sh node2:` pwd `/
scp Anaconda3-2021.05-Linux-x86_64.sh node3:` pwd `/其余步骤和node1安装一致
在其余两台虚拟机上配置pyspark虚拟环境
将node1的/etc/profile 和 /root/.bashrc 新增的配置文件,复制到node2和node3中的相同文件中
在node1将spark改成hadoop用户
chown -R hadoop:hadoop spark*
3.3.3 配置spark相关配置文件
在node1进入到spark的配置文件目录中, cd $SPARK_HOME/conf
配置workers文件
1 | 改名, 去掉后面的.template后缀 |
配置spark-env.sh文件
1 | 1. 改名 |
在HDFS上创建程序运行历史记录存放的文件夹:
1 | hadoop fs -mkdir /sparklog |
配置spark-defaults.conf文件
1 | 1. 改名 |
配置log4j.properties 文件 [可选配置]
1 | 1. 改名 |
将INFO改成WARN

这个文件的修改不是必须的, 为什么修改为WARN. 因为Spark是个话痨
会疯狂输出日志, 设置级别为WARN 只输出警告和错误日志, 不要输出一堆废话.
3.3.4 将配置好的spark文件分发到其他服务器
1 | scp -r spark-3.2.0-bin-hadoop3.2 node2:/export/server/ |
不要忘记, 在node2和node3上 给spark安装目录增加软链接
ln -s /export/server/spark-3.2.0-bin-hadoop3.2 /export/server/spark
检查:
检查每台机器的:
JAVA_HOME
SPARK_HOME
PYSPARK_PYTHON
等等 环境变量是否正常指向正确的目录
启动历史服务器:
sbin/start-history-server.sh
使用jps指令查看:

使用 ps -ef|grep 57895 来查看jobhistoryserver的信息
启动spark的Master和Worker进程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17启动全部master和worker
sbin/start-all.sh
或者可以一个个启动:
启动当前机器的master
sbin/start-master.sh
启动当前机器的worker
sbin/start-worker.sh
停止全部
sbin/stop-all.sh
停止当前机器的master
sbin/stop-master.sh
停止当前机器的worker
sbin/stop-worker.sh查看Master的WEB UI
默认端口master我们设置到了8080
如果端口被占用, 会顺延到8081 …;8082… 8083… 直到申请到端口为止
可以在日志中查看, 具体顺延到哪个端口上:
Service 'MasterUI' could not bind on port 8080. Attempting port 8081.

3.3 连接到StandAlone集群
bin/pyspark
执行:
1
2
3bin/pyspark --master spark://node1:7077
通过--master选项来连接 StandAlone集群
不写 --master选项,默认是local模式运行bin/spark-shell
1
2bin/spark-shell --master spark://node1:7077
同样适用--master来连接到集群使用bin/spark-submit(PI)
1
2bin/spark-submit --master spark://node1:7077 /export/server/spark/examples/src/main/python/pi.py 100
同样使用--master来指定将任务提交到集群运行查看历史服务器WEB UI
历史服务器的默认端口是: 18080
我们启动在node1上, 可以在浏览器打开:
node1:18080来进入到历史服务器的WEB UI上.

3.4 Spark应用架构
Spark Application运行到集群上时,由两部分组成:Driver Program和Executors。
Driver Program :
- 相当于AppMaster,整个应用管理者,负责应用中所有Job的调度执行;
- 运行JVM Process,运行程序的MAIN函数,必须创建SparkContext上下文对象;
- 一个SparkApplication仅有一个
Executors:
- 相当于一个线程池,运行JVM Process,其中有很多线程,每个线程运行一个Task任务,一个Task任务运行需要1 Core CPU,所以可以认为Executor中线程数就等于CPU Core核数;
- 一个Spark Application可以有多个,可以设置个数和资源信息;

用户程序从最开始的提交到最终的计算执行,需要经历以下几个阶段:
- 用户程序创建 SparkContext 时,新创建的 SparkContext 实例会连接到 ClusterManager。 Cluster Manager 会根据用户 提交时设置的 CPU 和内存等信息为本次提交分配计算资源,启动 Executor.
- Driver会将用户程序划分为不同的执行阶段Stage,每个执行阶段Stage由一组完全相同Task组成,这些Task分别作用于待处理数据的不同分区。在阶段划分完成和Task创建后, Driver会向Executor发送 Task.
- Executor在接收到Task后,会下载Task的运行时依赖,在准备好Task的执行环境后,会开始执行Task,并且将Task的运行状态 汇报给Driver.
- Driver会根据收到的Task的运行状态来处理不同的状态更新。 Task分为两种:一种是Shuffle Map Task,它实现数据的重新 洗牌,洗牌的结果保存到Executor 所在节点的文件系统中;另外一种是Result Task,它负责生成结果数据
- Driver 会不断地调用Task,将Task发送到Executor执行,在所有的Task 都正确执行或者超过执行次数的限制仍然没有执行成 功时停止
3.5 Spark程序运行层次结构
4040: 是一个运行的Application在运行的过程中临时绑定的端口,用以查看当前任务的状态.4040被占用会顺延到4041.4042等 (4040是一个临时端口,当前程序运行完成后, 4040就会被注销哦 )。
8080: 默认是StandAlone下, Master角色(进程)的WEB端口,用以查看当前Master(集群)的状态 。
18080: 默认是历史服务器的端口, 由于每个程序运行完成后,4040端口就被注销了. 在以后想回看某个程序的运行状态就可以通过历史 服务器查看,历史服务器长期稳定运行,可供随时查看被记录的程序的运行过程。
运行起来一个Spark Application
1
2
3/export/server/spark/bin/pyspark --master spark://node1:7077
打开运行如下spark命令
sc.textFile("hdfs://node1:8020/input/words.txt").flatMap(lambda line:line.split(" ")).map(lambda x:(x,1)).reduceByKey(lambda a,b:a+b).collect()打开其4040端口,并查看:

在node1运行pyspark-shell,WEB UI监控页面地址:http://node1:4040
可以发现在一个Spark Application中,包含多个Job,每个Job有多个Stage组成,每个Job执行按照DAG图进行的

其中每个Stage中包含多个Task任务,每个Task以线程Thread方式执行,需要1Core CPU
Spark Application程序运行时三个核心概念:Job、Stage、 Task
job
由多个 Task 的并行计算部分,一般 Spark 中的 action 操作(如 save、collect,后面进一步说明),会生成一个 Job。
Stage
job 的组成单位,一个 Job 会切分成多个 Stage ,Stage 彼此之间相互依赖顺序执行,而每个 Stage 是多 个 Task 的集合,类似 map 和 reduce stage。
Task
被分配到各个 Executor 的单位工作内容,它是 Spark 中的最小执行单位,一般来说有多少个 Paritition (物理层面的概念,即分支可以理解为将数据划分成不同 部分并行处理),就会有多少个 Task,每个 Task 只会处 理单一分支上的数据。


四、环境搭建-StandAlone HA
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master 单点故障(SPOF)的问题。

4.1高可用HA
如何解决这个单点故障的问题,Spark提供了两种方案:
基于文件系统的单点恢复(Single-Node Recovery with Local File System)–只能用于开发或测试环境。
基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)–可以用于生产环境。
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active 的,其他的都是Standby。当Active的Master出现故障时,另外的一个Standby Master会被选举出来。由于集群的信息 ,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对 于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示:


4.1.1 安装配置Zookeeper
简介
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
除了为Hadoop和HBase提供协调服务外,Zookeeper也被其它许多软件采用作为其分布式状态一致性的依赖,比如Kafka,又或者一些软件项目中,也经常能见到Zookeeper作为一致性协调服务存在。
Zookeeper不论是大数据领域亦或是其它服务器开发领域,涉及到分布式状态一致性的场景,总有它的身影存在。
安装
Zookeeper是一款分布式的集群化软件,可以在多台服务器上部署,并协同组成分布式集群一起工作。
在node1上操作下载zookeeper安装包并解压
1
2
3
4
5
6
7
8下载
wget http://archive.apache.org/dist/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
确保如下目录存在,不存在就创建
mkdir -p /export/server
解压
tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz -C /export/servernode 1上创建软链接
1
ln -s /export/server/apache-zookeeper-3.6.3-bin /export/server/zookeeper

node 1 上修改配置文件
1
2
3
4
5
6
7
8
9
10
11
12zookeeper 提供了示例配置文件将其改名再修改即可
cd /export/server/zookeeper/conf/
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改如下配置
dataDir=/export/server/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888node 1 上配置myid (标识操作,防止机器间错乱)
1
2
3
4
5
61. 创建Zookeeper的数据目录
mkdir /export/server/zookeeper/data
2. 创建文件,并填入1
vim /export/server/zookeeper/data/myid
在文件内填入1即可node 1 操作将zookeeper复制到node2 和 node3
1
2
3
4cd /export/server
scp -r apache-zookeeper-3.6.3-bin node2:`pwd`/
scp -r apache-zookeeper-3.6.3-bin node3:`pwd`/node 2 操作
1
2
3
4ln -s /export/server/apache-zookeeper-3.6.3-bin /export/server/zookeeper
2. 修改myid文件
vim /export/server/zookeeper/data/myid
修改内容为2node 3 操作
1
2
3
4ln -s /export/server/apache-zookeeper-3.6.3-bin /export/server/zookeeper
2. 修改myid文件
vim /export/server/zookeeper/data/myid
修改内容为3【在node1、node2、node3上分别执行】启动Zookeeper
1
2启动命令
/export/server/zookeeper/bin/zkServer.sh start # 启动Zookeeper【在node1、node2、node3上分别执行】检查Zookeeper进程是否启动
1
2jps
结果中找到有:QuorumPeerMain 进程即可
【node1上操作】验证Zookeeper
1
2
3
4
5
6/export/server/zookeeper/zkCli.sh
进入到Zookeeper控制台中后,执行
ls /
如无报错即配置成功
至此Zookeeper安装完成



4.2 基于ZooKeeper实现HA
4.2.1 Spark StandAlone HA环境搭建
前提: 确保Zookeeper 和 HDFS 均已经启动
先在spark-env.sh中, 删除: SPARK_MASTER_HOST=node1

原因: 配置文件中固定master是谁, 那么就无法用到zk的动态切换master功能了.
在spark-env.sh中, 增加:
1 | SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha" |
将spark-env.sh 分发到每一台服务器上
1 | scp spark-env.sh node2:/export/server/spark/conf/ |
停止当前StandAlone集群
1 | sbin/stop-all.sh |

启动集群:
1 | 在node1上 启动一个master 和全部worker |

检查node2 的master进程绑定的端口 输入 netstat -anp | grep 57923

发现在8083端口监听,浏览器输入 node2:8083 可以看到:

或者 进入spark的logs文件夹查看master日志文件 也能发现其绑定在了8083端口上:

4.2.2 测试主备切换
进入node1 输入jps:

准备指令kill -9 49432先不运行,先到node2上提交一个spark 任务到当前alive 的master上:
1 | node2 在spark目录下操作 |
在活跃的master界面我们可以看到一个正在运行的spark程序:

然后运行刚刚哪个kill指令将这个活跃的master kill掉 我们发现并不会影响程序的运行,依旧给出了正确结果:

然后我们进入到 node2 上的备用master界面,发现其状态从STANDBY变成了ALIVE:

现在回到node1重新启动spark-master:
sbin/start-master.sh

我们发现其状态变成了STANDBY
结论 HA模式下, 主备切换 不会影响到正在运行的程序.
最大的影响是 会让它中断大约30秒左右.
五、Spark On YARN (重点)
5.1 简介
按照前面环境部署中所学习的, 如果我们想要一个稳定的生产Spark环境, 那么最优的选择就是构建:HA StandAlone集群。
不过在企业中,都基本上会有Hadoop集群. 也就是会有YARN集群. 对于企业来说,在已有YARN集群的前提下在单独准备Spark StandAlone集群,对资源的利用就不高. 所以, 在企业中,多数场景下,会将Spark运行到YARN集群中。
YARN本身是一个资源调度框架, 负责对运行在内部的计算框架进行资源调度管理. 作为典型的计算框架, Spark本身也是直接运行在YARN中, 并接受YARN的调度的.
所以, 对于Spark On YARN, 无需部署Spark集群, 只要找一台服务器, 充当Spark的客户端, 即可提交任务到YARN集群 中运行.
Spark On YARN 本质 ?
Master角色由YARN的ResourceManager担任.
Worker角色由YARN的NodeManager担任.
Driver角色运行在YARN容器内 或 提交任务的客户端进程中
真正干活的Executor运行在YARN提供的容器内
Spark On YARN 需要 ?
- YARN 集群
- Spark 客户端工具, 比如spark-submit, 可以将Spark程序提交到YARN中
- 需要被提交的代码程序 ,如spark/examples/src/main/python/pi.py此示例程序,或我们后续自己开发的Spark任务

5.2 环境搭建
确保:
- HADOOP_CONF_DIR
- YARN_CONF_DIR
在spark-env.sh以及环境变量中即可

连接到YARN中:
bin/pyspark
1
2
3
4
5bin/pyspark --master yarn --deploy-mode client|cluster
--deploy-mode 选项是指定部署模式, 默认是 客户端模式
client就是客户端模式
cluster就是集群模式
--deploy-mode 仅可以用在YARN模式下注意: 交互式环境 pyspark 和 spark-shell 无法运行 cluster模式

在yarn界面点击 applicationmaster会自动跳转到spark的master UI界面,这是由yarn的webproxysever提供的

bin/spark-shell
1
2
3bin/spark-submit --master yarn --deploy-mode client|cluster
示例
bin/spark-submit --master yarn /export/server/spark/examples/src/main/python/pi.py 100



5.3 部署模式DeployMode
Spark On YARN是有两种运行模式的,一种是Cluster模式一种是Client模式. 这两种模式的区别就是Driver运行的位置.
Cluster模式即:Driver运行在YARN容器内部, 和ApplicationMaster在同一个容器内

Client模式即:Driver运行在客户端进程中, 比如Driver运行在spark-submit程序的进程中

两种模式的区别


5.3.1 client 模式测试
假设运行圆周率PI程序,采用client模式,命令如下:
1 | # 在hadoop用户下 cd到spark目录下 |
打开spark 的历史服务器,我们会发现driver没有logs日志,因为,driver没有运行在yarn内部
日志结果全部通过终端输出:


5.3.2 cluster 模式测试
同样的命令程序,采用cluster模式:
1 | # 在hadoop用户下 cd到spark目录下 |
此时我们会发现,终端不会输出结果,此时我们在spark 的history服务器上点开driver 的日志我们看到其输出,或者在yarn管理界面点击logs同样能看到日志和结果输出


5.4 两种模式详细流程
在YARN Client模式下,Driver在任务提交的本地机器上运行,示意图如下:

具体流程步骤如下:
- Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster ;
- 随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的 ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存;
- ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分 配指定的NodeManager上启动Executor进程;
- Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数;
- 之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后 将Task分发到各个Executor上执行
在YARN Cluster模式下,Driver运行在NodeManager Contanier中,此时Driver与AppMaster合为一体,示意图如下:

具体流程步骤如下:
- 任务提交后会和ResourceManager通讯申请启动ApplicationMaster;
- 随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的 ApplicationMaster就是Driver;
- Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请 后会分配Container,然后在合适的NodeManager上启动Executor进程;
- Executor进程启动后会向Driver反向注册;
- Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开 始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行
5.5 PySpark
5.5.1 是什么PySpark
我们前面使用过bin/pyspark 程序, 要注意, 这个只是一个应用程序, 提供一个Python解释器执行环境来运行Spark任务 我们现在说的PySpark, 指的是Python的运行类库, 是可以在Python代码中:import pyspark PySpark 是Spark官方提供的一个Python类库, 内置了完全的Spark API, 可以通过PySpark类库来编写Spark应用程序, 并将其提交到Spark集群中运行.
PySpark类库和标准Spark框架的简单对比:

5.5.2 安装PySpark类库
在 三台虚拟机上进入之前conda创建好的pyspark环境中,运行 pip install pyspark

六、本机开发环境搭建
6.1 本机PySpark环境配置
Haddop DDL
- 将hadoop-3.3.0文件夹复制到:D:\study\hadoop-3.3.0
- 将文件夹内bin内的hadoop.dll复制到: C:\Windows\System32里面去
- .配置HADOOP_HOME环境变量指向 hadoop-3.3.0文件夹的路径
配置这些的原因是: hadoop设计用于linux运行, 我们写spark的时候 在windows上开发 不可避免的会用到部分hadoop功能 为了避免在windows上报错, 我们给windows打补丁
Anaconda和PySpark安装
打开 anaconda prompt 执行以下操作:
创建虚拟环境
conda create --prefix=D:\envs\pyspark python=3.8--prefix是一个选项,用于指定要创建的conda环境的路径切换到创建的虚拟环境
conda activate D:\envs\pyspark在虚拟环境安装包
pip install pyhive pyspark jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
6.2 vscode配置Python解释器
安装必要插件
Remote-SSH
然后点击remote-ssh的config设置,改成如下:

然后连接虚拟机服务器,输入密码后可以进入到远程环境中,此时会自动找到虚拟机安装好的python环境



6.2.1 PyCharm配置Python解释器
加远程连接
点击右下角添加新的解释器,然后选择ssh连接到虚拟机

输入ip和用户连接服务器后,选择anaconda创建的虚拟环境解释器:



6.3 应用入口:SparkContext
Spark Application程序入口为:SparkContext,任何一个应用首先需要构建SparkContext对象,如下两步构建:
创建SparkConf对象
设置Spark Application基本信息,比如应用的名称AppName和应用运行Master
第二步、基于SparkConf对象,创建SparkContext对象
wordcount示例:
1 | # coding:utf-8 |
如果本地文件和虚拟机上文件不同步的话可以尝试重新上传:

注意:
如果要在windows本地运行代码的话,需要配置pysaprk的环境变量


运行原理:

注意的是如果使用yarn模式的话,文件地址如果使用的是本地文件的话一定要保证每个机器都能访问到,要不然会报错。
Spark Core
一、RDD详解
1.1 RDD是什么
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,一种容错的、可并行操作的数据结构,用于在集群应用程序中共享数据;是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。所有的运算以及操作都建立在 RDD 数据结构的基础之上。
可以认为RDD是分布式的列表List或数组Array,抽象的数据结构,RDD是一个抽象类Abstract Class和泛型Generic Type

1.2 RDD的五大特性
前三个特征每个RDD都具备,后两个特征可选的
RDD是有分区的

用代码演示:
cd 到spark目录下,输入
bin/pyspark运行终端,输入如下代码:
计算方法都会作用到每一个分区之上
使用map将每个数扩大十倍,我们会发现所有分区的数据都会进行变化,并不只改变一个分区:

RDD之间是有相互依赖关系(血缘关系)

KV型RDD可以有分区器




默认分区器:Hash分区规则,可以手动设置一个分区器(rdd.paritionBy的方法来设置)
不是所有RDD都是Key-Value型。
RDD分区数据的读取会尽量靠近数据所在的服务器
因为这样可以走本地读取避免网络读取.本地读取性能 >> 网络读取
spark会在确保并行计算能力的前提下,尽量确保本地读取,但这并不是100%的
二、RDD编程入门
2.1 程序执行入口 SparkContext对象
Spark RDD 编程的程序入口对象是SparkContext对象(不论何种编程语言) 只有构建出SparkContext, 基于它才能执行后续的API调用和计算本质上, SparkContext对编程来说, 主要功能就是创建第一个RDD出来

2.2 RDD的创建
RDD的创建主要有两种方式:
- 通过并行化集合创建(本地对象 转 分布式RDD)
- 读取外部数据源(读取文件)
并行化创建:
代码演示:
1 | # coding:utf-8 |
API:
1 | rdd = sparkcontext.parallelize(参数1,参数2) |
读取文件创建:
code:
1 | # coding:utf-8 |

API:
1 | sparkcontext.textfile(参数1,参数2) |
textFile 一般除了有很明确的指向性吗,一般情况下,不设置分区参数
另外还有专门读取一堆小文件的API:
1 | sparkcontext.wholeTextfile(参数1,参数2) |
这个api偏向于少量分区读取数据,文件的数据很小分区很多,导致shuffle的几率更高,所以尽量少分区读取数据
2.3 RDD算子
算子:分布式集合对象的api称之为算子
方法\函数:本地对象的api,叫做方法\函数
RDD的算子分为两类:
- Transformation:转换算子
- Action:动作算子
Transformation 算子
RDD算子,返回值仍然是一个RDD,称之为转换算子;这类算子是lazy 懒加载的,如果没有action 算子,Transformation算子是不工作的
Action 算子
返回值不是rdd的就是action算子
对于这两类算子来说,Transformation算子相当于在构建执行计划,action是一个
指令让这个执行计划开始工作.
如果没有action,Transformation算子之间的迭代关系就是一个没有通电的流水线
只有action到来,这个数据处理的流水线才开始工作.
2.4 常用Transformation算子
map算子
map算子 是将RDD的数据一条条处理,返回新的RDD
语法:
rdd.map(func)
#接收参数传入传入类型不限,返回一个返回值,返回值类型不限
flatMap算子
对rdd执行map操作,然后进行接触嵌套操作
解除嵌套:
1
2
3
4
5# 嵌套的list
lst = [[1,2,3],[4,5,6],[7,8,9]]
# 解除了嵌套
lst = [1,2,3,4,5,6,7,8,9]演示代码:
1
2
3
4
5
6
7
8
9
10
11
12
13# coding:utf-8
# 演示flatmap算子
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize(["a b c", "a c e ", "e c a"])
# 按照空格切分数据后,接触嵌套
print(rdd.flatMap(lambda x: x.split(" ")).collect())
reduceByKey算子
针对KV型RDD,自动按照key分组,然后根据提供的聚合逻辑,完成组内数据的聚合操作
用法:
1
2
3rdd.reduceByKey(func)
# func:(V,V) -> V
# 接收两个传入参数(类型要一致),返回一个返回值,类型和传入要求一致代码:
1
2
3
4
5
6
7
8
9
10
11
12# coding:utf-8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('b', 1)])
res = rdd.reduceByKey(lambda a, b: a + b)
print(res.collect())
reduceByKey 中接收的函数,只负责聚合,不理会分组,分组是自动by key来分组的
mapValues 算子
针对二元元组RDD,对其内部的二元元组Value执行map操作
语法:
1
2
3rdd.mapValues(func)
# func:(V) -> U ->U表示返回值
# 传入的参数是二元元组的value值,只value进行处理代码:
1
2
3
4
5
6
7
8
9
10
11
12
13# coding:utf-8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('a',1),('a',11),('a',6),('b',3),('b',5)])
# 将二元元组的所有value都乘以10进行处理
print(rdd.mapValues(lambda x:x*10).collect())groupBy 算子
将rdd的数据进行分组
语法:
1
2
3
4rdd.groupBy(func)
# 传入一个函数,返回一个返回值,类型无所谓
# 这个函数是拿到你的返回值后,将所有相同返回值的放入一个组中
# 分组完成后,每一个组是一个二元组,key就是返回值,所有同组的数据放入一个迭代器对象中作为value代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# coding:utf-8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 2), ('b', 3)])
# 通过groupby对数据进行排序
res = rdd.groupBy(lambda x: x[0])
# lambda函数意思是将元组的value强制转换成list对象 下面两种方法都可
print(res.mapValues(lambda x:list(x)).collect())
# print(res.map(lambda x: (x[0], list(x[1]))).collect())
Filter 算子
过滤想要的数据进行保留
语法:
1
2
3rdd.filter(func)
# func: (T) -> bool 传入一个参数随意类型,返回值必须是t or f
# t被保留,f被丢弃代码:
1
2
3
4
5
6
7
8
9
10
11
12
13# coding:utf-8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 保留奇数
print(rdd.filter(lambda x: x % 2 == 1).collect())
distinct 算子
对RDD数据进行去重,返回新的RDD
语法:
1
2rdd.dinstinct(参数1)
# 参数1,去重分区数量,一般不用传代码:
1
2
3
4
5
6
7
8
9
10
11# coding:utf-8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 2, 3, 4, 5, 5, 6, 7, 6, 6])
print(rdd.distinct().collect())
join 算子
对两个RDD执行join操作(可实现SQL的内\外连接)
join算子只能用于二元元组
语法:
1
2
3rdd.join(other_rdd)
rdd.leftOuterJoin(other_rdd) # 左外
rdd.rightOuterJoin(oter_rdd) # 右外代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# coding:utf-8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 部门id和员工姓名
x = sc.parallelize([(1001, "a"), (1002, "bb"), (1003, "ccc"), (1004, "dddd")])
# 部门id和部门名称
y = sc.parallelize([(1001, "sales"), (1002, "tech")])
# join是内连接
# 对于join算子来说关联条件,按照二元元组的key来进行关联
print(x.join(y).collect())
# leftOuterjoin是左外连接 同理还有右外连接
print(x.leftOuterJoin(y).collect())union 算子
2个rdd合并成1个rdd返回
用法:
rdd.union(other_rdd)注意:
- 只合并,不会去重
- 不同类型的rdd依旧可以混合
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# coding:utf-8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([1, 1, 2, 3, 4])
rdd2 = sc.parallelize([5, 5, 4, 3, 6, 8])
union_rdd = rdd1.union(rdd2)
print(union_rdd.collect())
intersection 算子
求2个rdd的交集,返回一个新的rdd
用法:
rdd.intersection(other_rdd)代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# coding:utf-8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd1 = sc.parallelize([('a', 1), ('b', 1)])
rdd2 = sc.parallelize([('a', 1), ('c', 1)])
rdd3 = rdd1.intersection(rdd2)
print(rdd3.collect())

glom 算子
将RDD的数据,加上嵌套,这个嵌套按照分区来进行
比如rdd数据[1,2,3,4,5]有两个分区,那么,被glom后数据变成[[1,2,3],[4,5]]
使用方法:
rdd.glom()与GetNumPartitions不同的是,GetNumPartions只能看到分区数目,而glom算子能看到每个分区的数据分布;
代码:
1
2
3
4
5
6
7
8
9
10# coding:utf-8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8, 9], 3)
print(rdd.glom().collect())
groupBykey 算子
针对KV型RDD,自动按照key分组
用法:
rdd.groupBykey()自动按照key分组代码:
1
2
3
4
5
6
7
8
9
10
11
12# coding:utf-8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('a', 1), ('b', 2), ('a', 1), ('b', 2), ('a', 1), ('c', 2)])
group_rdd = rdd.groupByKey()
print(group_rdd)
sortBy算子
对RDD数据进行排序,基于指定的排序依据
语法:
1
2
3
4rdd.sortBy(func,ascending=False,numPartitions=1)
# func:(T) -> U:告知按照rdd中的哪个数据进行排序,例如lambda x:x[1]表示按照rdd中的第二列元素进行排序
# ascdeing True 升序 False 降序
# numPartions:用多少分区排序注意:若要全局有序,排序分区数请设置为1
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# coding:utf-8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('a', 1), ('a', 2), ('a', 1), ('a', 3), ('d', 2), ('c', 3), ('f', 5)])
# 按value排序
print(rdd.sortBy(lambda x: x[1], ascending=True, numPartitions=2).collect())
# 按key排序
print(rdd.sortBy(lambda x: x[0], ascending=False, numPartitions=1).collect())
sortByKey 算子
针对KV型RDD,按照key进行排序
语法:
sortByKey(ascending=True,numpartitons=None,keyfuc=<function RDD.lambda >)keyfunc:再排序前对key进行处理,语法是(K) -> U 一个参数传入,返回一个值
代码:
1
2
3
4
5
6
7
8
9
10
11
12# coding:utf-8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("test").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd = sc.parallelize([('a', 1), ('E', 1), ('d', 1), ('V', 1), ('f', 1), ('p', 1),
('n', 1), ('m', 1), ('L', 1), ('r', 1), ('h', 1), ('j', 1)], 3)
# 这里key是str但是通过强转之后可以调用lower()方法,将其转换成小写,防止大小写影响结果
print(rdd.sortByKey(ascending=True, numPartitions=1, keyfunc=lambda key: str(key).lower()).collect())











案例
需求:读取data文件夹中的order.txt文件,提取北京的数据,组合北京和商品类别进行输出,同时对结果集进行去重,得到北京售卖的商品类别信息
代码:
1 | # coding:utf-8 |

将案例部署到集群运行:
这里注意使用命令:hadoop fs -chmod 777 /user将hdfs文件文件夹权限修改,运行完后可以通过hadoop fs -chmod 755 /user修改回来,这里我提交到yarn运行时一直报错:root is not a leaf queue将yarn的配置文件yarn-site.xml中调度器的fair改成capacity再重启resourcemanager即可

1 |